Computational Imaging: Get the Image You Want
A number of factors make computational imaging more interesting for machine vision than ever before.

A basic PMS system uses a ring light with four 90 degree quadrants to cast a directional shadow around raised features on an object. The feature map can be applied through different algorithms to show surface details that are hard to find or can’t be detected in pure visual images.
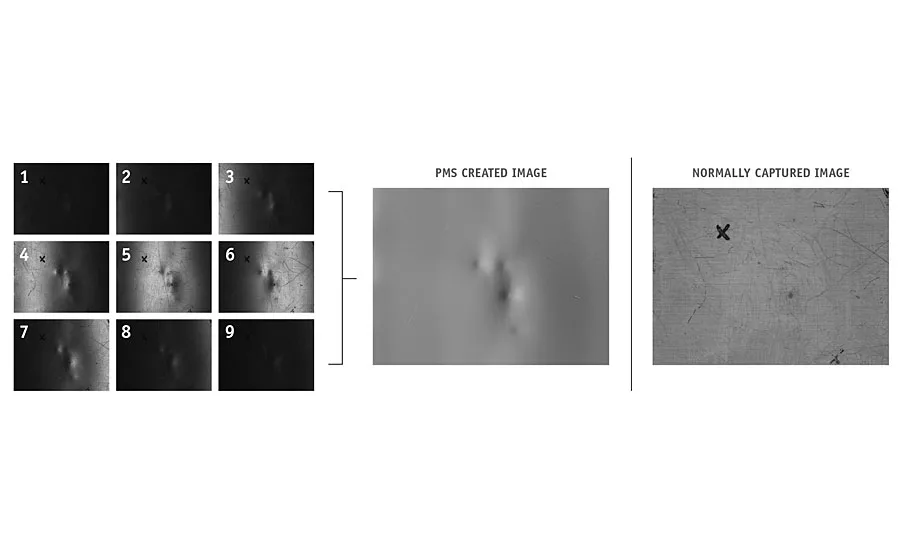
The images in this example were captured with a linear array of nine bar lights. The lights are fired from left to right in sequence to create a “sweeping effect” as the light passes over the imaging area in the center. A surface map can be created from the shading information. In the PMS image, the mild warping and dents are clearly visible and easy to detect. In the normally captured visual image of the same area, the same defects are difficult to detect amid the surface scratches and markings. The PMS routine removes the visual noise and leaves only the features of interest. Images courtesy of Visco Technologies Inc.

Three monochrome full resolution images are captured. To get the color information, each image is strobed with a single color: red, green, or blue. A color image with the full resolution of the monochrome camera can be created from the data of the three input images. In this example, three monochrome 8-bit 1600 x 1200 images are combined to make a 24-bit color 1600 x 1200 image.

Advantages of Composite Color Images
The advantages of this method to create composite color images become apparent as you zoom into feature details, as you might in a machine vision inspection.
In the zoomed image 1a, you can see the two exposed layers of the coil wire and the exit wire to the solder point. The edges are sharp and transitions are smooth with good contrast. In image 1b, the Bayer interpolation artifacts cause the wire to alias red + green along its length. Contrast to the background and between wire layers is reduced and noisy.
You can see similar effects in the 2a + 2b zoomed images. In the Bayer image 2b, the white silkscreen is almost completely Bayer noise. The red/gold/black boundaries of the test point in the lower corner become blurred and wider. In the 2a equivalent image, the silkscreen and test point are sharper, with good contrast and color.
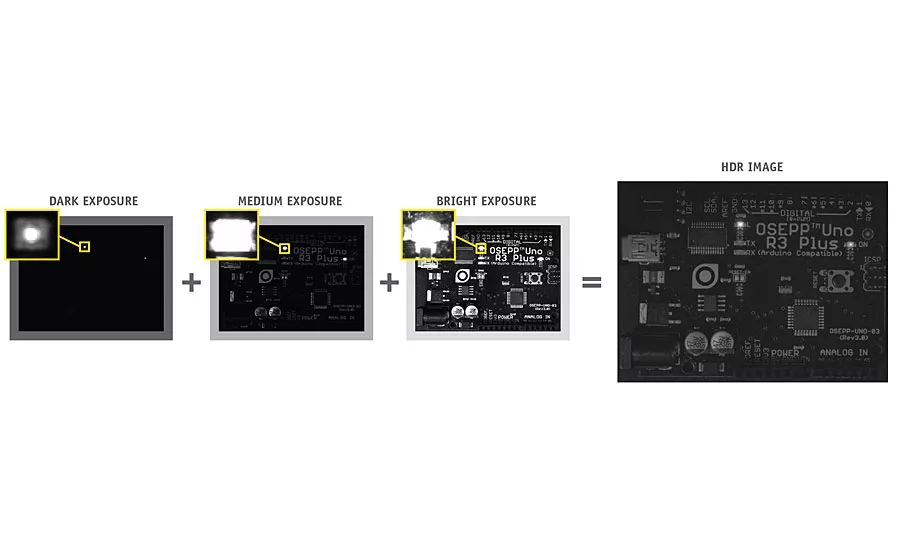
This HDR image is created from three images with different exposures. Image 1 lets you see the LED die and surrounding package, but no other details are visible. Image 2 exposure allows the silkscreen and brightest parts of the components to be seen, but the LED is oversaturated. Image 3 allows the barrel connector and other dark components to be seen, but the text and component leads are oversaturated; the LEDs are completely washed out. The HDR image allows correct exposure of the bright LEDs, proper saturation of the silkscreen and component leads, yet the dark components can still be seen.
You may not have noticed it, but there’s been a trend creeping into most of our lives. Its origins are rooted in consumer expectation. Consumers want to hold up their cell phones and snap the perfect selfie with the sun setting over the beach behind them. And they want to create panorama shots that challenge the best of wide angle lenses.
What do these two scenarios have in common? The answer is in how engineers solve the hard problems created by the common imaging conditions in the examples above.
In the case of the setting sun, the sun and sky are often thousands of times brighter than the subject of the selfie. The dynamic range of the small imagers used in cell phones is easily exceeded, yet the consumer expects to clearly see both their face and the brilliantly lit sky. To meet this expectation, many of the top cell phones now snap two or three pictures, each with a different exposure level in rapid succession. Invisible to the user, an algorithm in the background picks the most usable pixels in each image, weights them relative to each exposure level, and combines them into one single high dynamic range (HDR) image with a total dynamic range greater than possible with a single image capture.
Wide angle panorama images are created by grabbing many shots as the camera is swept left to right. An algorithm aligns each image to the last, merges the border between the two, and then repeats this for the next image in the sequence. The final wide angle panorama is a composite image created from the best pixels of all the aligned images and with a wider field-of-view (FOV) than would be possible with a single shot from a fixed imager and lens.
These techniques and many more are part of a trend to use multiple images to create a single computed output image and fit into an area called computational imaging. Computational imaging has slowly crept its way into the cameras on smart phones and other portable devices. Often unaware that the great image they just “snapped” is composed from multiple images captured in rapid succession, device users enjoy the exceptional images they expect in difficult situations without ever understanding the technical difficulties and limitations faced by the small format imagers used in most portable devices.
Advances in technology and the latest high speed CMOS cameras are making many computational imaging techniques viable for machine vision applications. System designers can start to think in new ways about creating solutions to difficult imaging problems using multi-image captures and treating the computed “super image” to create more robust solutions. Computational imaging can improve the capabilities of a camera or introduce features that were not possible at all. Better or previously impossible images for machine vision systems can be created at a lower cost.
A number of factors make computational imaging more interesting for machine vision than before. The starting point is computing power. Increased computing power is constantly increasing the capabilities of smart cameras and embedded computing. Many manufacturers are making vision specific embedded devices. With both more processing capability and speed, it’s more possible than ever to be implementing computational imaging techniques directly into the front end processing. Builders can choose the right amount of processing power; more is cheap.
The other main factor is higher performance CMOS imagers. Now commonplace in the market, the latest crop of high speed machine vision cameras can cover a range from VGA resolution at thousands of frames per second (fps) to 12 megapixel cameras capable of more than 160 fps. With trends toward higher speeds and resolutions coupled with improvements in sensitivity, the high speed CMOS trend is well suited to match the needs of the developing computational imaging market.
Computational imaging covers a wide range of techniques and processes. These include photometric stereo (shape from shading); HDR (high dynamic range) imaging; full color, full resolution image acquisition with monochrome cameras using sequential RGB lighting; extended depth of field (DOF) using sequences of images with varying focal points (Z-axis slicing); multi-spectral imaging with sequences of images timed to lights with varying spectrums; singly triggered, multiple camera acquisition for 360° object capture; and defect detection with structured lighting. These and many more possibilities allow vision system builders to choose a process to get the most beneficial image for their application at hand.
Computational imaging is easier than ever to implement into almost any vision system. Not sure of the benefits of computational imaging in practical machine vision solutions? Consider these three straightforward and easy to implement techniques next time you face a tough machine vision application.
Computational Imaging Technique 1 – Photometric Stereo (PMS)
Photometric stereo allows the user to separate the shape of an object from its 2D texture. It works by firing segmented light arrays from multiple angles and then processing the resulting shadows in a process called “shape from shading.” It is useful for the detection of small surface defects and 3D surface reconstruction. PMS is a height driven process which can enhance surface details like scratches, dents, pin holes, raised printing, or engraved characters. Because the final image is a computed surface based on the shading information surface coloring or features without height are removed. This can make visually noisy or highly reflective surfaces easier to inspect. This capability is rapidly becoming popular in the machine vision market. Numerous machine vision suppliers are offering photometric stereo tools.
Computational Imaging Technique 2 – High Resolution Color
Using a monochrome camera with a CCS full-color ring light, which has three-channel control of red, green, and blue output, the user can generate full resolution RGB color images at practical data rates. By grabbing a sequence of three monochrome images correlated to red, green, and blue strobes, a full color composite image at the full monochrome resolution can be created by aligning the images and using the red, green and blue values for each pixel to create the color pixel. The resulting composite color images are much sharper than that of a single image capture with a Bayer or mosaic color camera. The images are similar to those from three-CCD cameras without the expense, special prism or lens limitations, and at much higher resolutions than that of available three-CCD cameras.
The advantage of this method is the ability to have the best of both worlds: complete color information at the full pixel resolution of the imager. Due to the spatial effects of interpolation, Bayer color imagers capture the color information, but lose spatial resolution across several pixels.
Computational Imaging Technique 3 – High Dynamic Range (HDR) Imaging
All imagers have a limit to the ratio of the brightest object to the darkest object that can be distinguished in a single image. This is called the dynamic range. Many machine vision applications involve bright, shiny, or dark objects that challenge the dynamic range of the camera. To solve these cases, a series of images with different exposure level can be captured to create a single HDR image with all the detail that needs to be included for the inspection.
So next time you’re faced with a difficult imaging scenario, think not only of the right image, but look at which computational imaging techniques might get you the absolute best image. The examples mentioned here are only some of the many possibilities. If possible, think not in single images, but in what is possible in series of images. Then choose your lighting system and camera using one of the latest generation of high speed CMOS imagers that meets your computational imaging and application needs.
Looking for a reprint of this article?
From high-res PDFs to custom plaques, order your copy today!




