Vision & Sensors | Lighting
Simplify Deep Learning Systems with Optimized Machine Vision Lighting
Smart Lighting Improves Image Input Data for Effective Convolutional Neural Networks

Source: Smart Vision Lights
“Garbage in, garbage out” serves as a simple reminder that successful machine vision systems must start with quality data. Current challenges require flexible machine vision systems and models that can keep up with the speed of technology. Manufacturers have found value in partnering deep learning with machine vision to offer dynamic solutions that can compensate for lower-quality inputs. Despite deep learning compensation, however, starting with quality inputs will yield better results. The following explains the basics of rule-based and learning-based machine vision. Additionally, a case study presents evidence against the myth that learning-based solutions can compensate for lower-quality inputs in machine vision.
Getting Started With Deep Learning
Traditional machine vision systems use rules-based algorithms to make mathematical decisions, but certain applications may be difficult to describe mathematically, which presents a challenge. The ability to classify and label ambiguous or difficult-to-characterize images would benefit many types of machine vision systems. For example, machine vision challenges such as cosmetic flaw detection and final assembly verification are difficult to handle in a static or traditionally coded program. Training a system on data rather than algorithms offers a way to improve certain machine vision applications.
Implementing a deep learning system involves training convolutional neural networks (CNN) on data that makes it easier to deal with ambiguous or difficult characterizations, such as detecting cosmetic flaws. Obtaining optimal deep learning–based decisions in machine vision involves iteration. Images must be acquired under manufacturing lighting and part presentation conditions. Systems often require a large amount of sample images to capture part variation for accurate results and to reduce false negatives. Cosmetic flaw detection involves loading various part images into a deep learning system and labeling them as “good” or “bad.” These training images might include different orientations, lighting conditions, geometric dimensioning and tolerancing, flaws and failures, and any other variations that may be present during processing.
Knowing the possible or necessary variations for properly training the system by classifying and labeling each image, feature, character, flaw, and lighting change can present a challenge. Classification involves determining overall ground truth on good versus bad parts or identifying the type of defect present when using multiple classifiers. Labeling involves identifying specific defect locations or other features important for training the neural network. After training and development, deep learning–based machine vision must undergo statistical testing before being put into production. Like manual inspection processes, deep learning systems can only be qualified by measuring their performance over statistically valid datasets.
The phases of developing an AI/deep learning/machine learning machine vision solution.
Leveraging Advanced Lighting
Perhaps no aspect of vision system design and implementation has consistently caused more delays, cost overruns, and general consternation than lighting. Lighting does not inherently cause these problems, of course, but it often represents the last aspect specified, developed, or funded—if it’s dealt with at all. This may have been understandable in the days without vision-specific lighting (such as fluorescent or incandescent lamps and ambient light). Today, however, lighting can optimize nearly every aspect of machine vision systems and represents an essential system component.
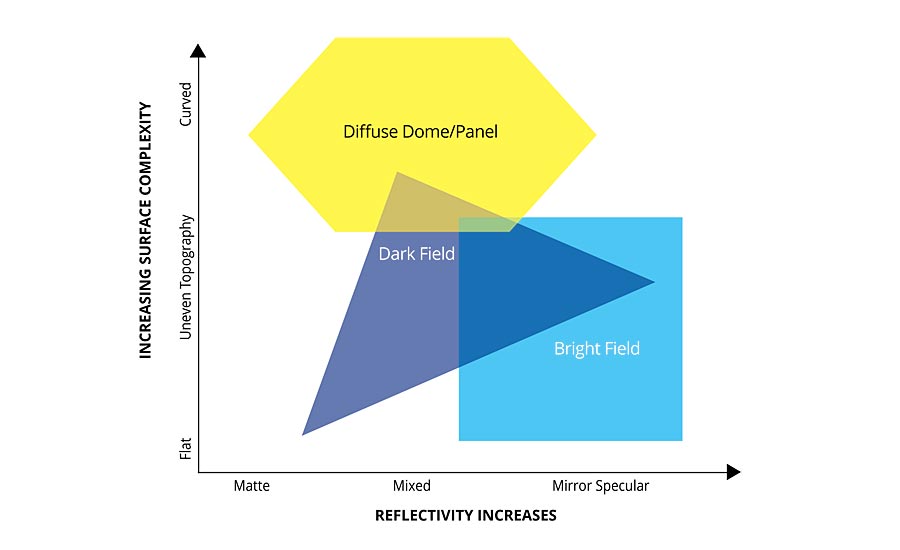
Lighting technique application areas. As you move down and to the right, more specialized lighting geometries and structured lighting types are needed. Any lighting technique is generally effective in the Geometry Independent Area (flat and diffuse surfaces). Source: Smart Vision Lights (Click on image to enlarge.)
Deep learning can help compensate for different imaging challenges, which leads some engineers to think that data may not be as critical as previously thought. For example, if deep learning can adjust for lighting, then lighting must not be as important. But the idea has not changed from “garbage in, garbage out.” Starting with the best, most accurate input data always yields a better result.

These images show the difference between lighting types. It is important to know what a machine vision application needs to capture, detect, and/or inspect to select the right lighting. No amount of deep learning compensation or digital filters can accurately verify data that is not in some form captured in an image. Source: Smart Vision Lights (Click on image to enlarge.)
Case Study: Good Vs. Bad Lighting Conditions
In a recent case study, a deep learning–based machine vision system inspected parts with both good and bad lighting with an objective of finding defects and measuring the performance of each lighting configuration. Defects varied from one to three per part and consisted of scratches and dents on an anodized surface. The training set consisted of 35 images of undamaged (good) parts and 35 images of damaged (bad) parts.
The 70 total images were used in good and bad lighting configurations, and the two datasets helped train a classification network. Each network was trained for a total of 30 epochs. One augmented image was generated for each image in the training set. The augmented images were created by flipping each image on both axes. The effective size of each dataset was therefore 140 images for each lighting configuration. Both networks using identical training and augmentation settings to ensure a good comparison.
This simple experiment showed that the performance of a deep learning surface inspection system is substantially better with an optimized lighting setup. A network trained with a good lighting configuration shows 12.85% greater accuracy than a network trained with a bad lighting configuration.
Does Lighting Matter?
A good lighting network had an overall accuracy of 95.71%, with an average inference time of 43.21 ms.
A bad lighting network had an overall accuracy of 82.86%, with an average inference time of 43.00 ms.

The top two images show a poorly lit part both with and without a flaw. In both cases, notice the reflections of LEDs, which can be confused with defects and create false positives. The bottom two images show how proper lighting highlights a defect without creating any false positives. Source: Smart Vision Lights (Click on image to enlarge.)
Deep learning cannot compensate for or replace quality lighting. This experiment’s results would hold true over a wide variety of machine vision applications. Poor lighting configurations will result in poor feature extraction and increased defect detection confusion (false positives).
Several rigorous studies show that classification accuracy reduces with image quality distortions such as blur and noise. In general, while deep neural networks perform better than or on par with humans on quality images, a network’s performance is much lower than a human’s when using distorted images. Lighting improves input data, which greatly increases the ability of deep neural network systems to compare and classify images for machine vision applications. Smart lighting — geometry, pattern, wavelength, filters, and more — will continue to drive and produce the best results for machine vision applications with traditional or deep learning systems.
Steve Kinney is the director of engineering for Smart Vision Lights as well as an active AIA member and a current member of the AIA Board of Directors. He has been a past chairman of the AIA’s Camera Link Committee, beginning with its inception in 1999. As chair of one of the major standards committees, he has also been a participant the G3’s Future Standards Forum. Kinney has also been a major material contributor and instructor for the AIA Certified Vision Professional (CVP) program in both the Basic and Advanced CVP Camera + Image Sensor Technology courses.
Looking for a reprint of this article?
From high-res PDFs to custom plaques, order your copy today!





