Vision & Sensors | Vision
Developments in Vision Systems: Deep Learning, Rapid Development Environments And Factory Integration
The move to Industry 4.0 requires better connectivity to enable data trasnfer and sharing between all components within the factory structure.
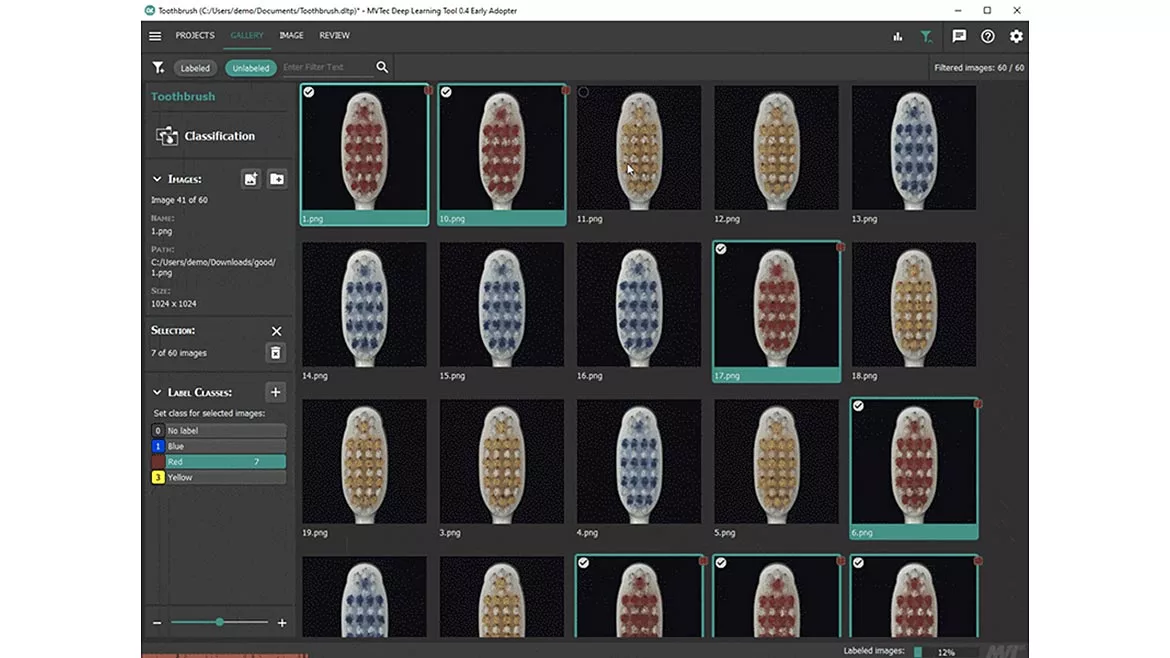
Figure 1. Point and click labelling of toothbrushes for classification. Courtesy of MVTec Software GmbH
Artificial intelligence in the form of deep learning continues to be one of the most important developments in machine vision in recent years. Using artificial neural networks to imitate the way the human brain works for recognition and decision-making, deep learning can enhance quality inspection in manufacturing environments by addressing problems that are difficult or impossible to handle with conventional rule-based machine vision algorithms. Deep learning is particularly good at object classification and the detection and segmentation of defects and has been deployed in many industries including automotive, aerospace, logistics, pharmaceuticals, semiconductor and traffic. It is also especially effective in sectors such as food and agriculture, since organic products have many natural variations that must be taken into account when assessing potential defects and classification issues. Deep learning is now more user-friendly and practical than ever and together with other vision technologies opens up new application areas, making the inclusion of vision inspection as part of Industry 4.0 even more beneficial.
Deep Learning Capabilities
The implementation of a deep learning system involves training a neural network with a set of images labelled to indicate different objects and/or defects to allow the system to learn to identify them. Figure 1 shows a series of images of toothbrushes labelled for training. The trained system is then used to evaluate output images from the actual application. These results can be linked into a process control system for quality control as well as providing valuable statistical data to help assess the cause of any problem to streamline the process and reduce waste. Classifying which category an item belongs to is an important capability provided by deep learning. Some classifiers simply yield a yes/no decision, while others can provide a number of classifications. Applications include defect identification, character recognition, presence detection, food sorting, etc.
Figure 2 shows the detection of a defect in a metal screw using a classifier. Anomaly detection is a recent addition to deep learning capabilities and acts as a ‘yes/no’ classifier. It has a particular benefit of needing only ‘good’ images for training and then if it detects any differences in the inspection images, these are flagged as ‘bad’ samples. Anomaly detection can be used on any application involving identification of defects on a surface or scene. In order to localize one or more objects of interest in an image, object detection methods can be used, which combines both localization and classification into a single operation. The technique can solve problems like presence detection, object tracking, defect localization and sorting, etc. Another critically important component of deep learning is image segmentation, which is used for defect sorting/qualification, food sorting, shape analysis, etc. The process simplifies analysis by dividing the input image into segmented groups of pixels representing objects or parts of objects instead of needing to consider individual pixels. Real world applications of deep learning include detecting complex surface and cosmetic defects, such as scratches and dents on reflective or turned surfaces. Defects can also be detected in woven materials or on pharmaceutical pills or on semiconductor contact surfaces. Deep learning can also be used for demanding OCR applications (even where the printing is distorted) including vehicle number plate reading. It is also particularly good for recognizing and classifying features and trimming positions on fruits, vegetables and plants, both for processing or automated harvesting. In logistics, it can be used to identify empty warehouse shelves.

Figure 2. Good and defective metal screws. The defect is shown as a heatmap output of a deep learning classification algorithm. Courtesy of Teledyne DALSA (Click on the image to enlarge.)
Simplifying Deep Learning Implementation
Deep learning tools are now available within all-in-one rapid development image acquisition processing and analysis software platforms. This point and click approach saves time and complexity in building deep learning solutions since it is no longer necessary to have the specialist programming skills that were needed when these tools could only be accessed from image libraries. Rapid deployment is further enhanced through the introduction of pre-trained neural networks, which can significantly reduce training time since they can be fine-tuned for the specific application using a much smaller set of training images than would otherwise be required. As discussed above, the availability of anomaly detection has also speeded up the development of deep learning systems as a new network can often be trained in just a few seconds, since only a relatively small number of ‘good’ images are required and no data in these images needs to be labelled. Just a few ‘bad’ images are needed for final testing. This method is extremely useful in applications where there are many variations, allowing differentiation between natural variations and genuine defects in natural products. The ‘pass/fail’ results obtained from using this method not only provide good quality control, but data from the failures can be accumulated to build up more specific classifiers to further enhance the selection process and reduce false rejects.
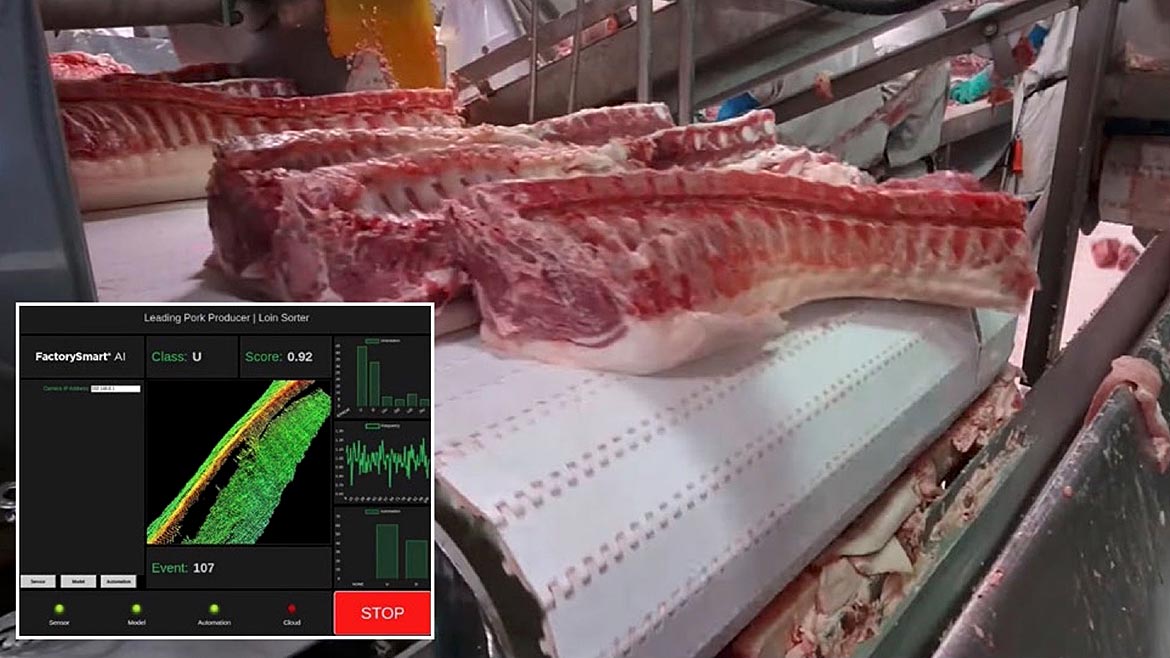
Figure 3. 3D classification of pork loins traveling on a high-speed conveyor. Courtesy of LMI Technologies Inc. (Click on the image to enlarge.)
Deep Learning And 3D Vision
3D imaging has been another major growth area in machine vision applications particularly in vision-guided robots, with direct interfacing between robots and 3D cameras now enabling their coordinate systems to be matched without needing a PC. Networking multiple 3D cameras together to a common coordinate system with the results from individual sensors combined into a single high-density 3D point cloud now enables 3D inspection of larger objects. It is even possible to link 3D laser line profilers with different resolutions in a combined coordinate system to enable simultaneous inspection of different regions of the same component at different resolutions. Deep learning methods are now also being deployed in 3D imaging applications in a similar approach to that used for 2D imaging. Proven standard neural networks are trained with sets of 3D images for object classification or the detection and segmentation of defects including anomaly detection before being used on live images. Figure 3 illustrates 3D classification of pork loins traveling on a high-speed conveyor. After acquiring 3D profiles of pork loins, the AI model performs an inline classification into left or right side cuts, based on height, minimum area, gap between samples, and maximum length and the resulting sort decision is sent to downstream machinery. Deep learning technology is also starting to be applied to robot vision applications. For example a neural network can be used with 3D data from a scene to evaluate the parts and their surfaces in order to select the optimum part to be picked.
Deep Learning At The Edge
Deep learning is computationally intensive and neural networks can be run in the cloud or on CPUs or GPUs at the edge of the network (as close as possible to the imaging source). While the networks can be set up, trained and optimized either at the edge or in the cloud, use on live images is most likely to be time-critical and therefore is best performed on the edge. This approach not only reduces the response time and bandwidth required, but is easily scalable, reduces latency for applications that require a rapid response and enhances security by minimizing data transfer. Compact, ruggedized industrial-grade design CPU/GPU combinations with significant computing power are now available to enable high speed GPU-accelerated AI computing at the edge. Data can be transferred to remote data centers or the cloud for use in improving the deep learning model if required or for long-term storage or distribution across multiple networks.
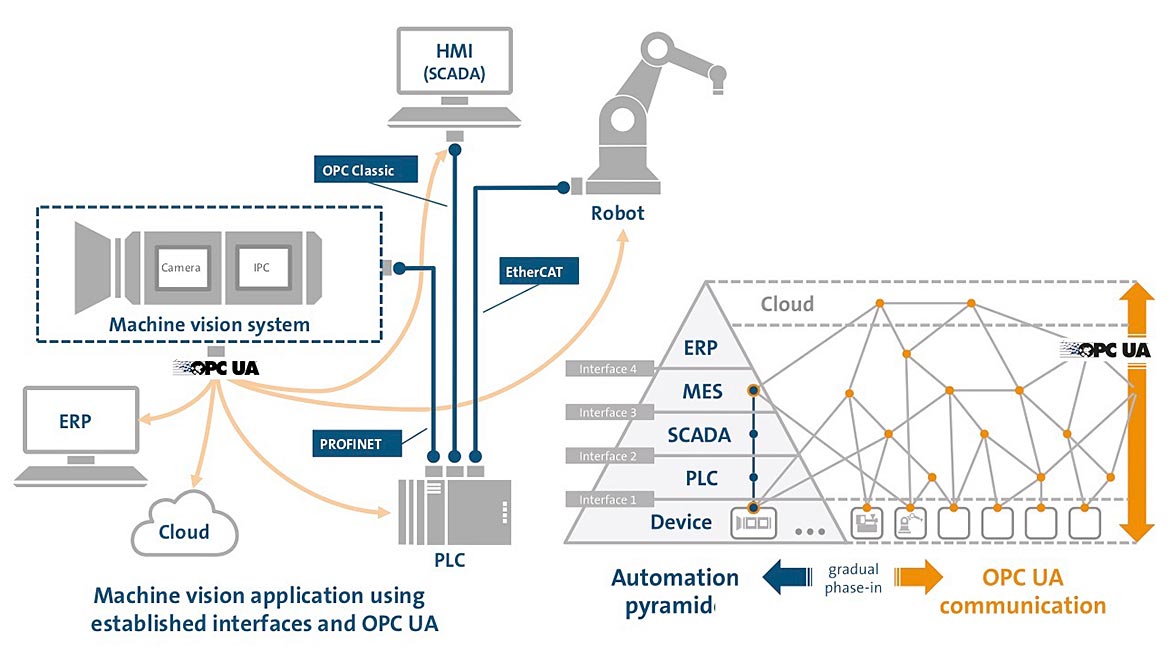
Figure 4. Phasing in of OPC Machine Vision. Courtesy of VDMA (Click on the image to enlarge.)
Enhancing Connectivity For Industry 4.0
While many vision systems have had direct interfacing to factory automation buses such as Ethernet IP, Profibus and Modbus, the move to Industry 4.0 requires better connectivity to enable data transfer and sharing between all components within the factory structure. The OPC UA platform-independent, open standard for machine-to-machine communications addresses these issues by providing a common communication protocol. Recently the VDMA (the Mechanical Engineering Industry Association in Germany) has developed OPC UA Companion Specification Vision (OPC Machine Vision) which is becoming available through commercially available machine vision software and complete ready to go machine vision systems. This provides a generic information model for all vision systems from simple vision sensors to complex inspection systems. OPC Machine Vision not only complements or replaces existing interfaces between a vision system and its wider process environment through the OPC UA standard, but enables the creation of new horizontal and vertical integration pathways for relevant data communication to other parts of the process right up to the IT enterprise level. In this way, OPC Machine vision allows the vision system to speak to the factory and beyond, with the ability to load jobs for vision systems from ERP systems and return batch results and statistics to the ERP system. Figure 4 shows how OPC Machine Vision can be phased in with blue lines showing conventional communication pathways and orange lines showing communication using OPC-UA.
Getting Back To Basics
While deep learning has greatly extended the reach and capabilities offered by machine vision, it must not be forgotten that for all imaging applications the imaging system itself must be correctly configured and set up to produce images of the required quality at the right speed. As deep learning opens up even more choices for the vision system developer, it is important to work with expert vision technology suppliers who can advise on all aspects of the vision system from the ground up ensuring the system is specified correctly.
Looking for a reprint of this article?
From high-res PDFs to custom plaques, order your copy today!





