Vision & Sensors | Trends
The Place for Deep Learning in Industrial Machine Vision
Deep learning is an "add on" to traditional machine vision. It does not eliminate the ability to handle a range of tasks using traditional tools.

In the last few years, deep learning has started to have a significant impact in the machine vision space. Deep learning has various meanings, some of which can be retroactively applied to long-used techniques. In this article, deep learning refers to developments during the last few years that have enabled applying the technique to entire images in the industrial machine vision space.
Deep learning has advantages and disadvantages compared to traditional machine vision. In this article, we seek to provide an understanding which will assist in deciding which approach to use. We’ll begin by describing aspects of each that are relevant to understanding these differences.
We’ll simplify this article by discussing only typical, practical, robust automatic inspection solutions utilizing 2D visible light imaging. Machine vision software discussions will be limited to those products that are developed to the point of being accessible to most technical automation professionals. And a “spoiler” at this point is helpful to absorb the information: deep learning’s current place in machine vision is to do the applications which are not possible or feasible using traditional machine vision.
The choice and comparison that we are discussing is about the way to accomplish certain main tasks of the application, not the entire application. Deep learning is an “add on” to traditional machine vision, it does not eliminate the ability or need to handle a range of tasks using traditional machine vision tools.
Successful machine vision is a process with many stages that span initial exploration through long-term ownership. A few of the middle stages are:
- Confirm feasibility: confirm that a feasible solution can be developed
- Create the “physics” side of the imaging solution, including lighting
- Program the vision unit.
Let’s take a closer look at the “physics” stage. This designs an interaction between lighting, the workpiece and the camera to create the reliable differentiation in the image needed to make the intended program work. “Differentiation” is usually determined by lightness/darkness or differences in color.
Let’s take an example, finding defects on a surface using traditional machine vision. We’ll look at an intended program that we need to design the “physics” solution for. This program will expect (only) the defects to be dark. It will convert every dark spot into an object for analysis, calculate one or more severity metrics for each (such as the area of the defect) and then apply a pass /fail rule that any defect larger than a certain area will cause the product to get rejected.
To function, this program requires more than reliable differentiation to operate, it also needs simple-rule differentiation. The “simple rule” is that all defects are dark, and all good parts of the surface are light.
For the above steps of a traditional machine vision program, it’s possible to know exactly what is intended to happen within each step and to see whether or not that step is working properly. This clarity and visibility often makes it possible to also shorten the work required during the feasibility confirmation phase. This is done by combining engineering expertise and lab work to quickly identify and verify the only questionable areas. This may reduce the cost of feasibility confirmation. For example, it can sometimes make that investment small enough that a solution vendor might confirm it for free prior to proceeding on the main project investment.
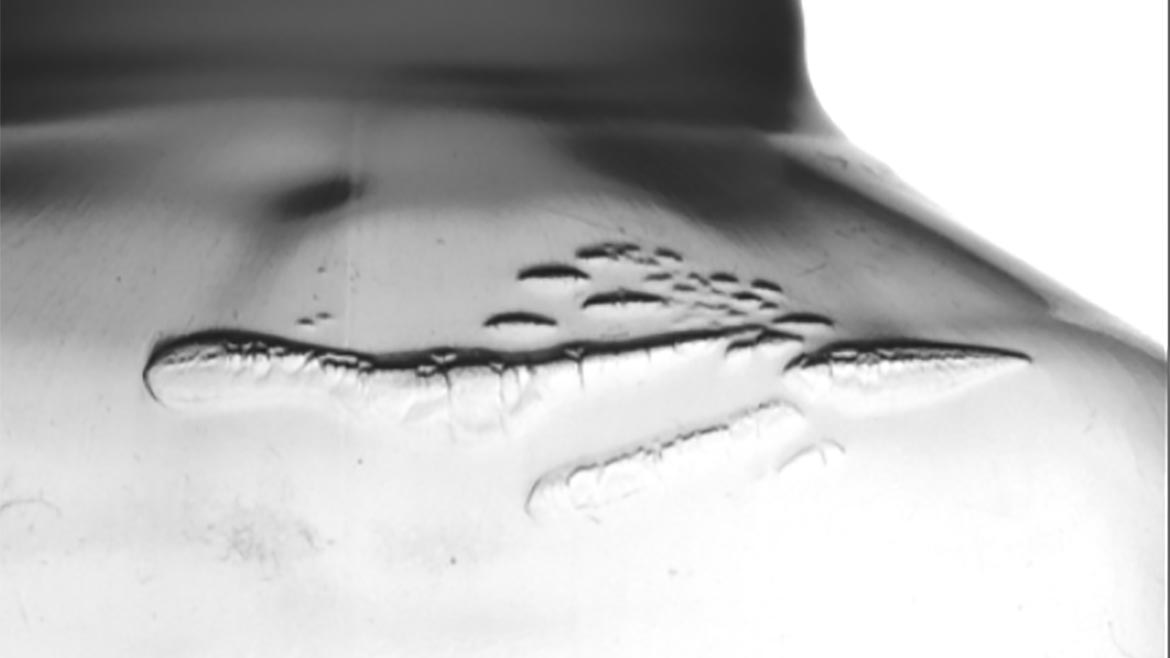
Figure 1 Source: FSI Technologies
Most applications that have not been possible or feasible to do with traditional machine vision are those where it is not possible to create the “simple rule” aspect of the differentiation. Figure 1 illustrates the type of challenge often involved. In that example, the goal is to find defects on the bottle that are completely transparent and thus normally invisible or hard to see. The image in figure 1 is the result of applying some techniques that make the defects visible (dark). The simple-rule goal is “defects dark, everything else light.” Unfortunately, the technique also makes perfectly good portions of the bottle dark, therefore the “simple-rule” goal was not achieved. This may make it unfeasible to do with traditional machine vision, or unnecessarily difficult compared to using deep learning.
Even though we don’t have “simple rule” differentiation, we still have differentiation. A human can look at a few of these images, and, combined with their experience with bottles, tell the difference between dark parts that are defects and those that aren’t. This situation occurs in a wide variety of other applications such as wood or fabric analysis, surface analysis on complex surfaces, or unclear OCR applications. This is where deep learning shines; if a human can reliably see it with one quick look and decide, it will probably be possible to accomplish utilizing deep learning. We say “one quick look” because humans often do other things not available in a machine vision solution. If they hold and manipulate the product, they are in essence taking 20 looks from varying angles and lighting geometries and if only one of the 20 attempts is successful, that is sufficient.
With deep learning, we still need the defects to be made reliably visible during the “physics” phase, but we no longer require “simple rule” differentiation. A typical process might be to acquire dozens or hundreds of images of good and bad products and then have a human identify and tag (annotate) them as good or defective, or identify the defects separately. After setting a fraction of them aside for final testing purposes, an early stage of software process might be augmentation where many more images are created by making minor variations in our training images. Some settings for the trial are put into the deep learning machine vision software and then the processor and software are launched into an effort to train itself to properly identify good and bad parts. With a fast computer, especially one with a reasonably strong GPU (graphics processing unit) the trillions of operations this process might require might be accomplished in “only” a few minutes or a few hours. When it’s done, it is then tested with the set-aside images that it hasn’t trained on. If unsuccessful, changes are made in the settings or images, and the process is repeated. When successful, what it has generated is called a “model.” The model may be moved to a less powerful processor for run-time execution, which is called “inference.”
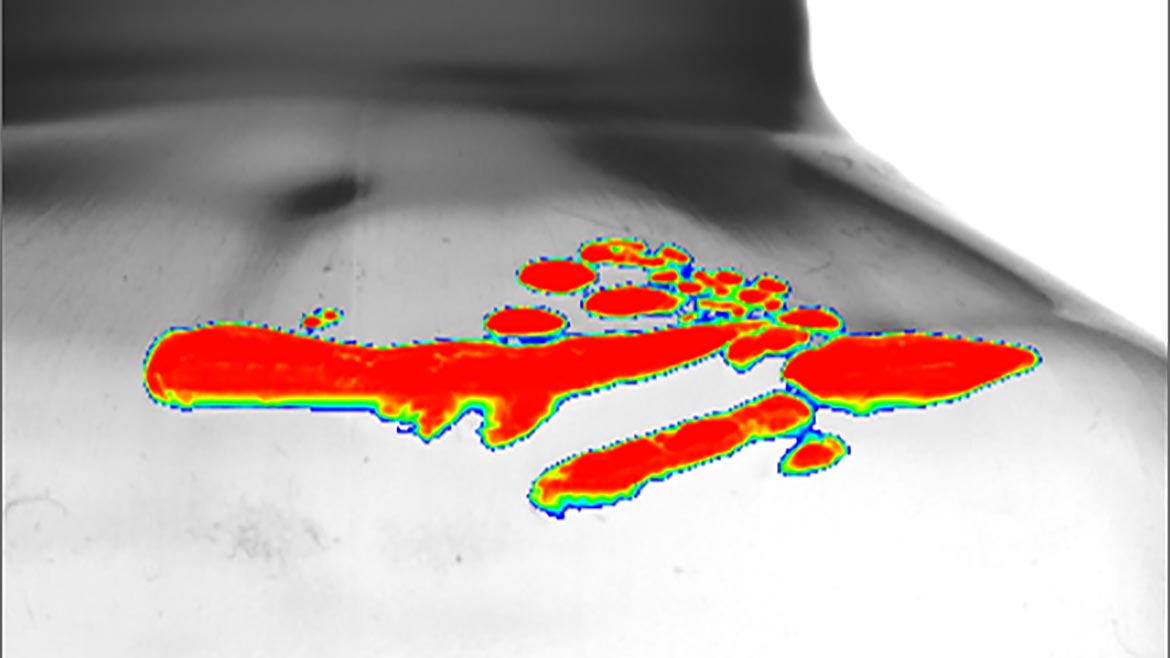
Figure 2 Source: FSI Technologies
Figure 2 shows one of the available displays of the results, a “heat map” which shades the areas that the model considers defective. Note that it successfully identified the defective areas and was able to ignore the large quantity and diversity of dark areas that are not defects.
The main advantage for deep learning is a huge one: it enables accomplishing inspections that were impossible, unfeasible or comparatively more difficult using traditional machine vision. We used a common “differentiation” example. A few other areas where it excels are decisions involving multiple weighted variables, or spotting commonalities in patterns such as in difficult OCR applications. Now let’s look at the disadvantages.
The cost for deep learning machine vision software is higher. A dollar difference of mid four figures for training-capable software is currently typical. The hardware cost for the computer that will be handling the training phase is also more expensive, typically to include a reasonably powerful GPU.
Deep learning tools involve more work at nearly every stage. This starts with acquiring and labelling larger numbers of images. Each stage of “trying out” something may take minutes or hours for the training phase processor to execute rather than milliseconds. This extra work occurs at all phases from the “confirm feasibility” phase to changes and tasks involved during long-term ownership.
Execution is no longer a series of totally predictable rules-based steps, instead it occurs inside of a profoundly complex “black box.” Reducing undesired results is no longer a process of finding a malfunction, instead one must repeat the training process using different images, annotations and settings to try to achieve better performance. Also, there are fewer engineering-based shortcuts available during feasibility confirmation thus requiring a larger investment for that phase.
Deep learning is not good at accomplishing many tests for simple explicit criteria which traditional machine vision handles well. This article did not expand on those because the simple recommendation to use traditional machine vision when it works covers those situations.
We also didn’t spend much space on the expertise level required. As with previous developments, claims range from “it will make machine vision a no-brainer” to “using it is so special and technical that I can’t explain it to a mere mortal.” In reality, it sometimes reduces the required expertise in some areas and increases it in others.
In summary, the place for deep learning in machine vision is to accomplish tasks that are not possible, not feasible or comparatively more difficult with traditional machine vision. This article has hopefully helped identify those. It looked at tactical considerations. Strategic factors may also influence the decision. For example, a company may choose deep learning for edge cases because they wish to explore or gain experience and expertise in this powerful and exciting expansion of machine vision technology.
Looking for a reprint of this article?
From high-res PDFs to custom plaques, order your copy today!






