Self-learning Intelligence for Object Recognition
More and more, advanced artificial intelligence technologies are being incorporated into machine vision systems.

Machine vision plays a key role in highly automated production processes.
Machine vision is a key technology for highly automated and seamlessly networked processes in the context of Industry 4.0, a.k.a. the Industrial Internet of Things. The use of new artificial intelligence processes such as deep learning is gaining in importance. A great many benefits make the technology attractive, but it also has limitations.
The automation of industrial production is advancing quickly. Fully networked and digitalized process chains have long been commonplace in production halls. In line with Industry 4.0 and the smart factory, all the components involved—including machines, robots, transfer and handling systems, sensors, and image acquisition devices—work together and communicate seamlessly with each other. A new trend is also catching on in robotics: Small, compact, and mobile robots known as collaborative robots (cobots) are joining the production processes and frequently cooperate closely with their human colleagues. The great benefit of cobots is that they can be retooled quickly and with minimal effort, making it possible to use them flexibly for different production tasks.
Complementary technologies that accompany and support the entire value creation process play an important role in these highly automated scenarios. These include, for example, programmable logic controllers (PLCs) and machine vision. The latter observes and monitors the production processes in real time as the “eye of production.” Image acquisition devices, such as cameras, scanners, and 3D sensors, are placed in multiple positions and record the processes from different perspectives. The generated digital image data is processed by integrated machine vision software and made available for a wide range of tasks in the process chain. For example, objects can be detected reliably and positioned accurately based on optical features. The technology also detects manufacturing faults in products and thus allows them to be removed automatically, thereby optimizing quality assurance processes.
Artificial intelligence for a comprehensive training process
More and more, advanced artificial intelligence (AI) technologies are being incorporated into machine vision systems. One such technology is deep learning, based on an architecture of convolutional neural networks (CNNs). Enormous quantities of digital image information are used for an extensive training process. Based on these data, the software can then independently classify new objects. During the training process, specific characteristics and features that are typical of a certain object class are learned automatically. New image data can thus be assigned precisely to their particular class(es), resulting in extremely high and robust recognition rates. These deep learning algorithms are also suitable for accurately locating objects and defects.

Machine vision acts as the “eye of production.”
Deep learning technologies are predestined for certain areas of use within machine vision applications. These primarily include classification, object detection, and semantic segmentation. This is where smart algorithms particularly show their strengths. In other machine vision applications, however, the suitability of deep learning is limited. Since vast quantities of data need to be analyzed, the training process generally requires very large computing capacities and appropriately dimensioned hardware. Especially in the case of extremely time-critical applications, a standard CPU is often inadequate. This applies, for example, to high-speed applications, such as high-precision measurement tasks and the localization of objects with millimeter or micrometer accuracy. In this case, deep learning algorithms would require 50 to 100 milliseconds on a standard CPU. However, such precise positioning should take only a few milliseconds. What’s needed here is a powerful GPU, which is often not available in hardware used for industrial purposes.
Variance-dependent use of deep learning
Deep learning is also not the best choice in industrial applications where the objects to be detected or identified are very similar—as is the case, for example, in the electronics and semiconductor industry. Since these components usually have a very similar appearance, only a few sample images are needed for training using traditional machine vision methods. In many cases, even a single image is sufficient to detect the objects reliably and locate them precisely. However, it only makes sense to use deep learning algorithms if at least 100 training images are available for each object. Machine vision tasks in which the objects to be recognized are extremely similar can therefore be solved better using conventional methods, such as rule-based software technologies. For reading data codes and bar codes in particular, heuristic methods are used instead of deep learning algorithms. The metric measurement of objects, such as subpixel-accurate contour extraction, also relies on heuristic methods.
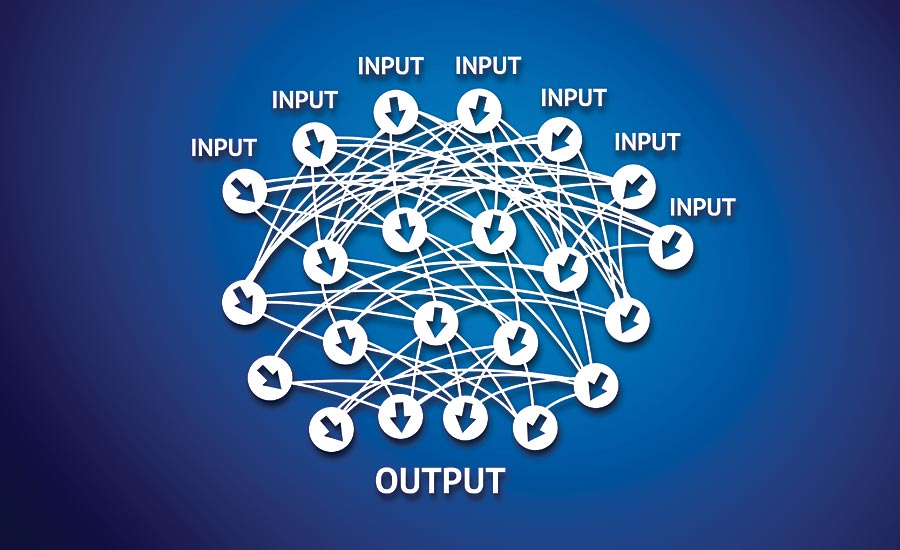
Deep learning ensures high recognition rates.
Nevertheless, in applications where deep learning can bring its full benefits to bear, certain challenges must be considered. Deep learning is a comparatively new technology for which the market provides few common standards. In addition, the overall handling of deep learning is extremely complex and requires in-depth knowledge as well as many years of experience in the areas of artificial intelligence, programming, and machine vision. This is often beyond companies’ capabilities, because they lack the necessary experts.
Less effort through pre-trained deep learning networks
However, there are ways in which companies can benefit from deep learning with a reasonable amount of effort. For example, they can take advantage of pre-trained deep learning networks. A number of free, open-source solutions are offered on the market for this purpose. Still, there are a few pitfalls to using them. For example, licensing problems can arise. Several hundred thousand sample images are generally needed to identify objects precisely. The reason such a large number is required is that many different features, such as color, shape, texture, and surface structure, are crucial to the recognition process. When selecting this large number of images, it is important to ensure that they are not subject to third-party rights—which is rarely guaranteed with open-source products.
Another challenge in using open-source tools is that they usually perform only certain machine vision tasks in isolation and are difficult to integrate into other applications or existing frameworks. Typical machine vision problems always involve several steps. First, the digital image data from the image acquisition device must be supplied to the particular application. The data is then preprocessed in a second step, in which the images are optimally oriented to place the objects in the desired position. Finally, the processed data is integrated into other solutions, such as a PLC, so that the results are seamlessly available for additional process steps. This is where open-source systems reach their limits.
Standard proprietary software scores points with many benefits
Proprietary standard software solutions that already have pre-trained networks are a more practical option for machine vision. These solutions include software that is equipped with all the important features for training deep learning networks. It can be optimally integrated into other applications, based on its wide range of functions and specially configured tools. The solution includes multiple networks that have been pre-trained based on approximately one million carefully selected, license-free images from industrial environments. Companies benefit by only requiring a few additional images to tailor the network training process to their own specific applications. This significantly reduces training effort, saves money, and avoids risks relating to image rights.
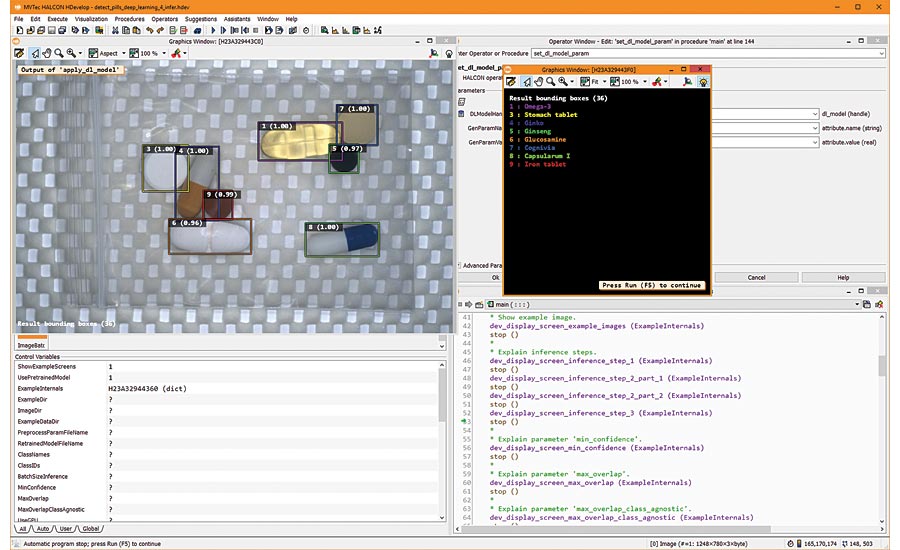
MVTec HALCON: With deep learning, objects can be detected precisely. Image Sources: MVTec Software GmbH / Fotolia
The use of open-source tools presents another challenge. Deep learning applications generally contain several hundred thousand lines of programming code. To operate without error, this code must satisfy certain quality criteria. The use of open-source code developed by an unknown community gives rise to certain risks in this regard. To be on the safe side, companies need to check the code internally to determine its quality. Due to the vast amount of code, this task is extremely labor-intensive and incurs almost incalculable costs. With a proprietary, commercial solution, however, companies benefit from high-quality, tested, and secure code. Should support be required, professional consultants and experts are available—something that can’t always be counted on with an open community.
Conclusion
In the age of digitalization and the Industrial Internet of Things, machine vision is an indispensable accompanying technology for highly automated and networked production processes. AI-based technologies, such as deep learning and CNNs, are important components of these machine vision solutions. However, it is important to keep in mind that they are suitable only for certain applications. Companies should also consider carefully whether an open-source system is adequate for their requirements or, instead, whether it would be worth their while to invest in a commercial, proprietary software solution. V&S
Looking for a reprint of this article?
From high-res PDFs to custom plaques, order your copy today!






