Vision & Sensors | Cameras
AI Vision Development for Everyone
The time it takes moving from a concept to a running application can be greatly reduced.

Unlike standard vision industrial cameras, AI or inference cameras belong to the device class of “embedded vision systems.” This presents manufacturers with completely new challenges. The task of implementing the power and resource hungry technology of neural networks efficiently and sustainably in small edge devices naturally is a major challenge. Another at least equally important part is how customers can work with devices and create their own applications with them.
Vision devices are ubiquitous now, and they no longer only use rules-based image processing; they work with machine learning algorithms. By shifting image processing and the generation of results to the edge device itself, the approach and handling of image processing tasks changes greatly.
With these shifts in mind, it’s necessary to find answers to essential questions such as:
- What interfaces does the device need, hardware and software-wise?
- Which tools can be provided to control, program or configure the device?
- Who are the target groups that implement these devices, and what skills do they need to succeed at this deployment?
The Embedded Challenge
Embedded vision systems are highly optimized devices that usually use components such as FPGAs (Field-Programmable Gate Array), GPUs (Graphical Processing Unit) or other ASICs (Application-Specific Integrated Circuit) in addition to a CPU to perform their specialized tasks extremely efficiently. As an openly programmable platform, such an edge device is a playground for experts who know how to address the various components and what tasks they can perform. But anyone who has programmed applications for an embedded device and had to set up the necessary development environment knows that this requires substantial prior knowledge. Knowledge not only regarding setting up the interaction between the development system and the edge device, but also knowledge of how to deal with interfaces, communication protocols, debuggers, toolchains and an IDE (Integrated Development Environment).
The potential capabilities of a new generation of AI-based devices will not only change the approach to creating image processing tasks, but also lead to new use cases. This in turn will expose entirely new user groups to vision and AI. For these new target groups, the barrier to entry into the world of embedded vision is still far too high. Device manufacturers need to keep this goal in mind: anyone should be able to design their own AI-based image processing and run it on an edge device, even without this aforementioned specialized knowledge. This results in completely new requirements for embedded vision development. The classic code-based programming SDK for software engineers is no longer the right working tool for everyone, nor is it sufficient to cover the entire embedded vision workflow.
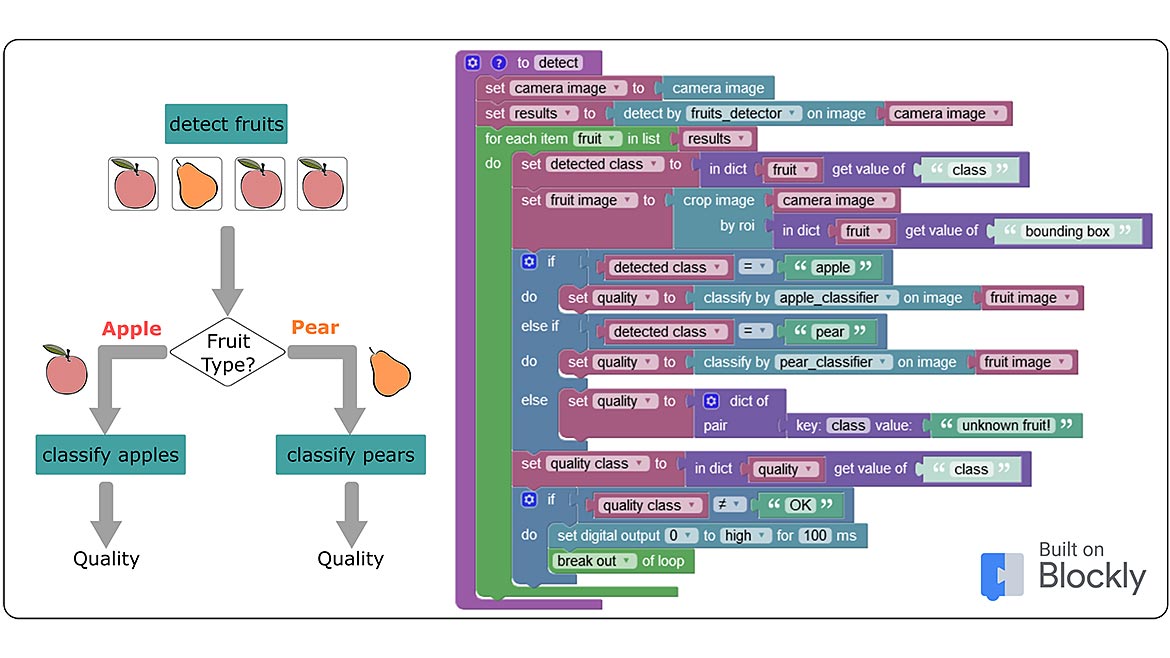
Figure 1. Visual programming allows all types of users to solve complicated problems, including ones that use multiple Convolutional Neural Networks (CNNs). Image Source: IDS Imaging Development Systems Inc.
Cloudy Development
Today, the development of an AI vision workflow for an edge device no longer needs to be platform-specific with a direct device connection. If the basic device functions are available in a universally configurable, modular function kit, the edge device would not have to be reprogrammed or code cross-compiled each time. The training of the ML algorithms can already be done completely independently of the device anyway. What’s missing then is only a “description” of the application workflow. That is, how the functions have to be combined with each other. Today, you no longer have to master a special text-based programming language for this interaction.
In being given this “high-level development environment,” the user neither has to deal with platform-specific programming nor with the special syntax of a programming language. The entire development with an AI-based embedded vision system takes place on a single software platform in the cloud. The user can fully concentrate on what the application is supposed to do, and they can do that without needing access to a physical device. For both app creation and initial tests, the user can access images or entire data sets that are also used for training the neural networks. In this way, the functionality of their app can be fully simulated. Of course, testing on physical hardware should occur before deployment, but you can use the app to run through special situations with suitable test data sets and debug them step by step before running the app in the camera.
Workflow Description
There is also potential for simplification in the “description” of an application workflow. On one hand, a more application-oriented approach makes it possible to reach a goal quickly and as simply. On the other, more overview and knowledge about the device functions also help to create more freedom in the design of the process.
An example of simplifying the workflow could be introducing a kind of “interview mode” that supports the user at the start of a project. The user would be presented with a selection of ready-made use cases, simple queries, as well as tips that guide them through the entire process of app creation. Without having to know specifically what type of neural network needs to be deployed, the right components are put together in the background to find their desired objects, count them and make the results available later via the selected device interfaces. After that, the user is told what kind of images to upload according to the chosen use case and also how to label them. The “interview mode” software would then create suitable data sets from the images with annotations and then train a neural network. In just a few steps, a complete embedded vision app is created in the cloud that the user can upload, activate, and run directly on their camera. In this way, many simple use cases can be fully realized.

Figure 2. An AI camera runs multiple Convolutional Neural Networks to locate multiple different types of objects in a scene. Image Source: IDS Imaging Development Systems Inc.
Block By Block
When more complex sequences are needed, such as a two-stage analysis by fruit type and quality (requiring multiple neural networks), there is no need to immediately switch to C++ or another text-based programming language and leave the comfort of cloud development behind. Visual editors have always lent themselves well to this approach. An example of this approach is using a block-based code editor that uses Google's “Blockly” library. In Blockly, processes can be combined like puzzle pieces in sequences of various complexities. This enables a much higher flexibility of the application description, while at the same time making the process easy to follow. Thanks to an intuitive user interface, even beginners can quickly produce successful results.
The advantage of block-based programming over an “interview mode” is the possibility to create your own sequences. Variables, parameters and AI results can be easily connected by logical links with mathematical calculations, conditional if/else statements, recurring actions through loops, or even the use of multiple neural networks.
Take for example, the two-stage analysis according to fruit type and quality: An object detector provides a basic pre-sorting of different parts, followed by a detailed error analysis by a second classifier to categorize the parts even more precisely. Such procedures are otherwise only possible with a more complex development environment and text-based programming knowledge. The user can start with an easy-to-use “interview mode” first and go deeper at any time if the application requires a little more customization due to the complexity of the problem.
Instant Apps
Another side effect worth mentioning of this simplified app creation is that “vision apps” created in this way can be easily changed dynamically. Since the basis of the application should already include all available device functionalities in a fully platform-specific, pre-compiled form as a construction kit, it has a universal and platform-independent interface. This means that the actual workflow can be changed or rewritten dynamically at any time, even while the application is running. Time-consuming cross-debugging and recompiling of the application is no longer necessary. This means that further development can also take place directly in the camera on the machine if required.
And The Winner Is...
With cloud-based AI vision development, there will be a suitable entry point into the development of image processing applications for every user group with different levels of prior knowledge. This means that completely new target groups will be (co-)involved in the development of applications. For example, the machine operator can make small adjustments at any time and thus continuously improve a process. The maintenance of an application will be easier and the quality can be increased more easily while reducing the development costs. And most importantly of all: with this approach to development tools, the time it takes moving from a concept to a running application can be greatly reduced.
Looking for a reprint of this article?
From high-res PDFs to custom plaques, order your copy today!



.webp?height=200&t=1751549950&width=200 "Toradex x FRAMOS - Partnership (1920 x 1080 px).jpg")

