Vision & Sensors | Machine Vision 101
Image Processing for Machine Vision – How Did We Get Here?
Machine Learning (ML) has been part of machine vision image processing almost from the beginning.

Figure 1 — Basic Machine Vision Image Processing Sequence | Images Source: Automated Vision Systems Inc.
Progress in machine vision processing is charted in major developments that prove significant staying power. One of the first was blob analysis introduced around 1977 as part of the SRI Algorithm. Blob analysis remains a major component of machine vision software. Another was the introduction of morphology around 1985. Morphology also remains part of the image processing tool kit. Then there was geometric pattern matching introduced into machine vision around 1997. It too remains a major tool in machine vision image processing.
Machine vision image processing (shown in Figure 1) consists of a chain of processes typically starting with preprocessing and then followed by segmentation, feature extraction, and interpretation. Preprocessing uses algorithms that transform an image into an image, such as low-pass filtering to remove noise or edge detection to find the edges of objects in the image. Preprocessing is not needed in all machine vision applications. Segmentation isolates the individual objects or the features on an object to allow them to be individually analyzed. Not all applications need segmentation. All applications do need feature extraction – getting feature values out of the image that characterize the properties that are significant for the application. Interpretation often uses logic and calculations to determine if the part is an accept or reject, which bin the part should be sent to, or where to direct the robot to go.
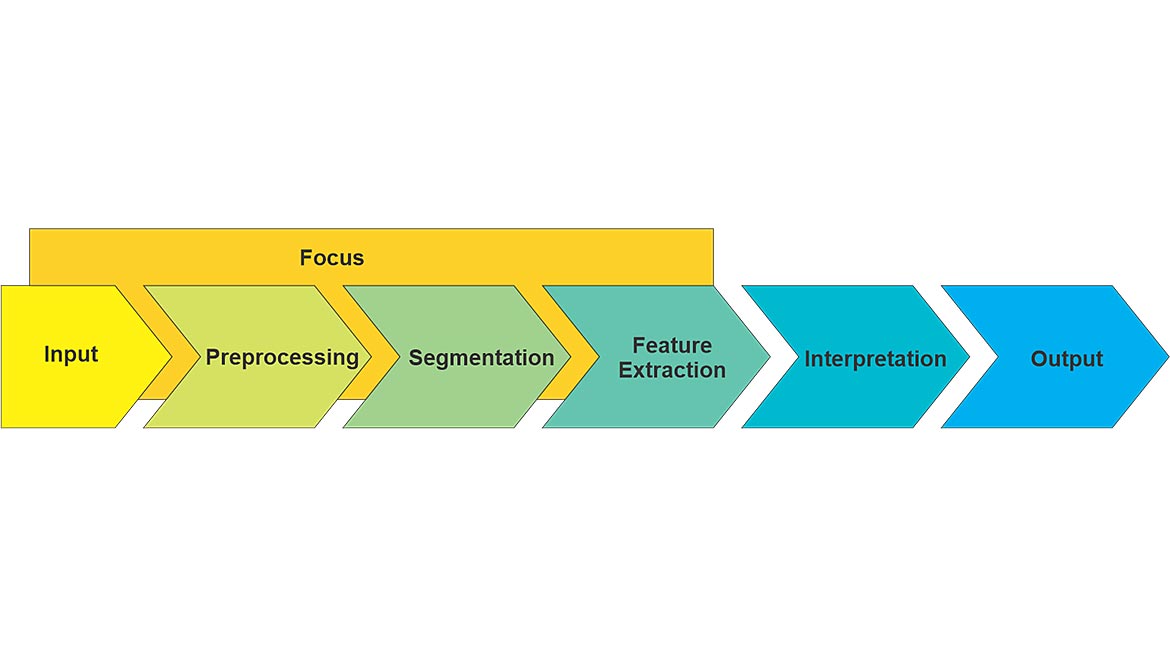
Figure 2 — Machine Vision Image Process with Focus (ROI) | Image Source: Automated Vision Systems Inc.
Very frequently, machine vision incorporates one or more regions-of-interest (ROIs) to focus processing on a specific area of the image. (See Figure 2.) This has the advantage of limiting the computational burden and excluding artifacts in the image that are not of interest and might interfere with the results of the processing. A ROI can be applied to preprocessing, segmentation, and feature extraction. It can also be applied in the camera or internal to the image processing or both. The ROI can be applied to the image to constrain further processing or it can be integrated into an algorithm to direct where in the image that algorithm will operate. Because features are not part of an image, the ROI is not applicable to interpretation. Interpretation can associate specific features with a given ROI used for their extraction.
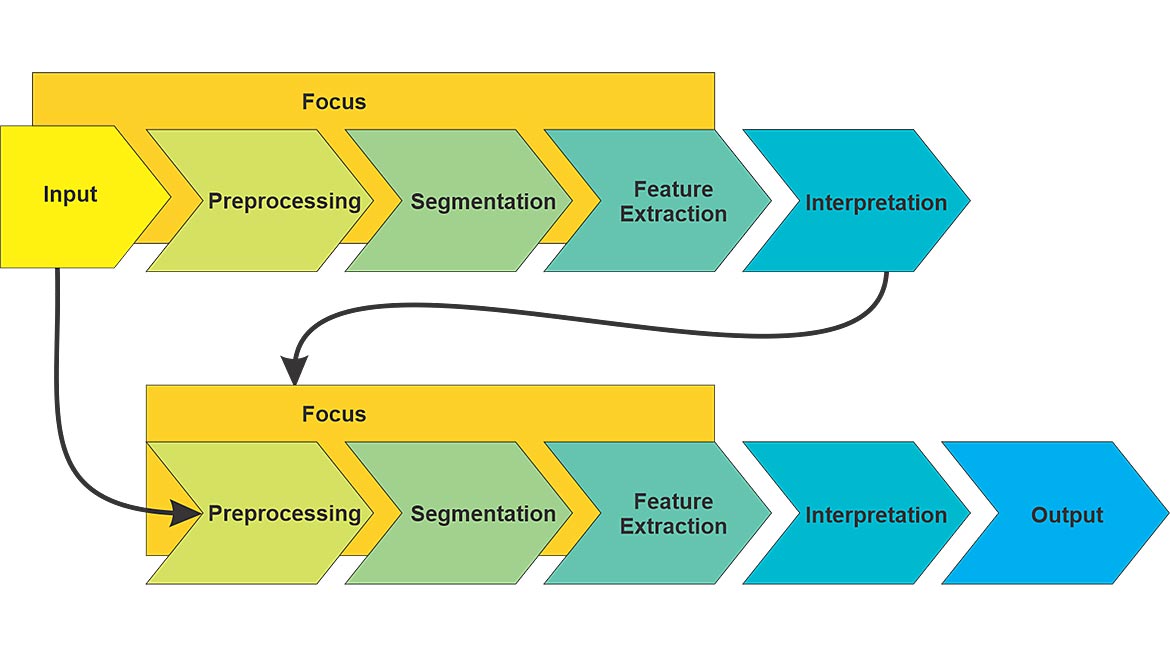
Figure 3 — Machine Vision Image Processing with Fixturing
When there are multiple parts in an image or when parts arriving under the camera are not physically constrained, their locations and orientations can vary. In that instance, a preliminary image processing step is performed to find the location(s) and rotation(s) of the part(s). The results of the preliminary step are used to move and rotate the ROIs for the principal image processing sequence to correspond to the part’s pose as shown in Figure 3. This is called fixturing or coordinate transforming.
Machine vision application developers found that selecting from among hundreds of available algorithms and tuning them required a high level of expertise and significant time to provide a system that functioned well. In response, machine vision software suppliers began providing tools to perform a range of common applications such as optical character recognition (OCR), calibration, measurements, bead inspection, and many others. This led to more efficiency in developing many machine vision applications. When appropriate tools are not available, traditional programming with its associated impacts must be employed.
Machine learning (ML) has been part of machine vision image processing almost from the beginning. The SRI algorithm incorporated nearest neighbor classification. Other, more sophisticated, classification techniques such as k-nearest neighbors and linear classifiers were available. In the 1980’s neural networks (NN) were available for use in machine vision, but never widely adopted.
About five years ago saw the introduction of deep learning (DL) using convolutional neural networks (CNN) (see Figure 4) into machine vision with explosive adoption. Without question, DL will remain an important part of machine vision image processing for a long time.
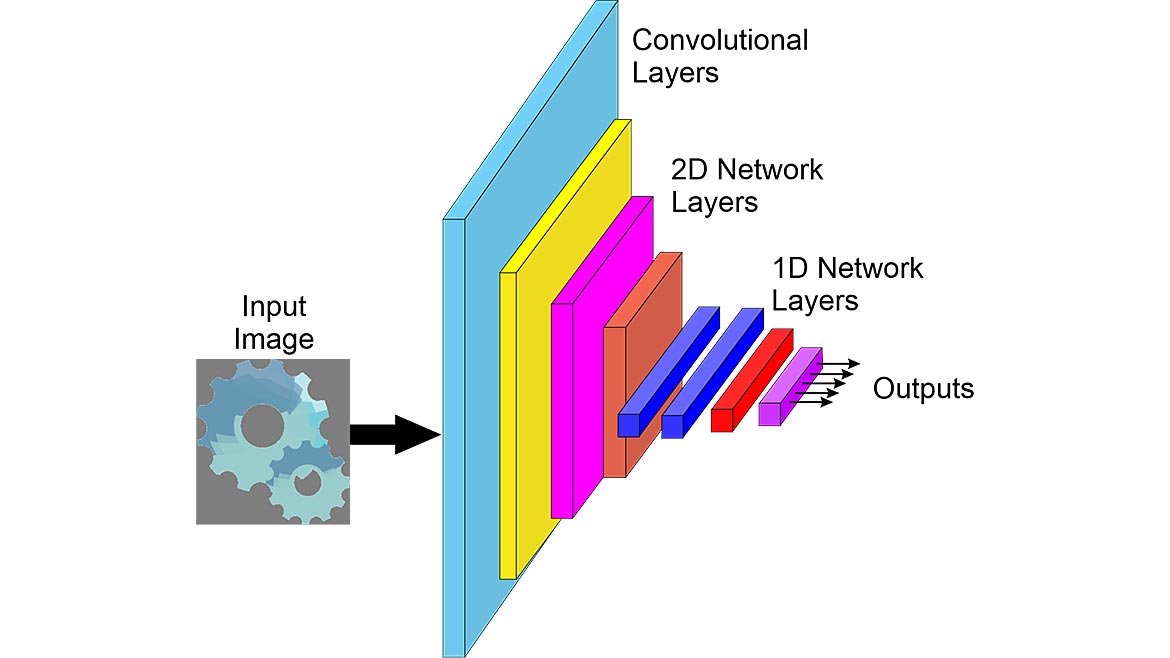
Figure 4 — Convolutional Neural Network (CNN)
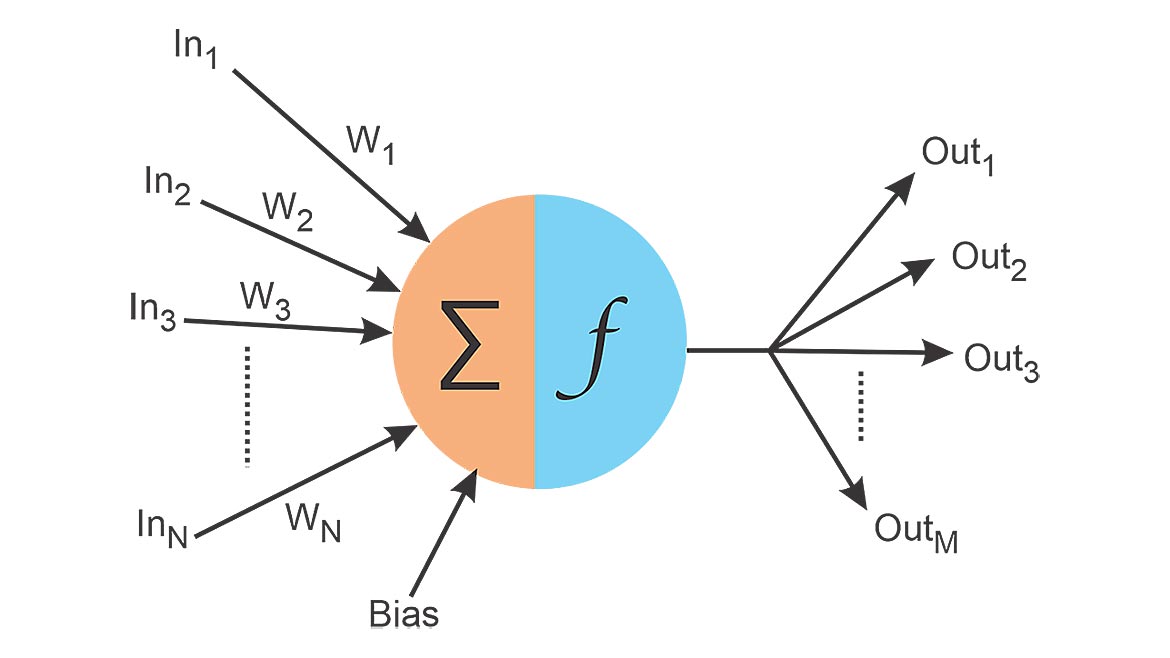
Figure 5 — Artificial Neuron
Each layer consists of an array of individual artificial neurons. (See Figure 5.) These neurons have inputs, weights associated with each input that are learned, a bias that is also learned, and an activation function.
Vision & Sensors
A Quality Special Section
In a CNN, the early layers are convolutions with weights that are learned. It is possible that these layers could perform low-pass filtering and edge detection. However, before training, there is no knowledge what convolutional functions will be learned by the network.
After the convolutional layers, there are more 2D layers of artificial neurons. The consensus is these layers extract features similar to feature extraction in traditional machine vision programming. The 1D layers of artificial neurons perform what is analogous to interpretation – determining the amplitude of each of the outputs.
While the layers of a CNN can be inferred to correlate to steps in traditional machine vision programming, this inference is likely misleading. There is no way to know in advance how the network will train and what each layer will do. Even after successful training to perform well, there is no predictable way to describe what is going on with the network and predict or explain exactly how it arrives at a particular output. Training a network from scratch two times results in different learned weights for the individual neurons – even when the performance of the two networks is nearly identical.
What distinguishes DL from more traditional machine vision image processing? With traditional machine vision image processing, a programmer chains a selection of algorithms or software tools together to provide the solution. Sometimes, traditional machine vision programming is referred to as rule-based programming because the series of algorithms is similar to a set of rules for implementing the process. In DL, programming is accomplished by training the CNN using a set of labeled images. Machine learning (ML) is often called programming with data where, in machine vision, images are the data.
The output of a CNN is not definitive. For example, suppose a CNN is trained to recognize capital letters of the alphabet. The CNN will have 26 outputs with each output corresponding to one of the letters. When the CNN executes, there is a value at each of the 26 outputs. Usually, one output has a value much higher than any of the other output to indicate the most likely letter. Still, this output is virtually analog, and additional logic is required to implement a crisp binary decision. Then there is the challenge with very similar characters, say an “O” and a “Q”. Those two outputs will both be higher than other outputs with one of the two higher than the other. Logic, in the form of rules, is needed to provide the final crisp selection.
While training a CNN is not difficult, mostly it takes time and computational resources. The set of labeled images often takes considerable labor to carefully prepare. Any mislabeling will significantly degrade the performance of the network. Training uses the bulk of the labeled images. Validation and possibly testing uses the remaining labeled images. How big a set of images is needed depends on the diversity of the images, both objects and backgrounds that may be imaged by the camera. While there is no best practice established for the size of the image data set, people who are working with DL are suggesting the test set of images be between 10 and 20 percent of the total images, and the validation set be between 5 and 10 percent of the total images. The practice is swinging toward eliminating the test set except in demanding applications and just use training and validation sets. In that case the validation set should be 10 to 20 percent of the total number of images.
Traditional machine vision applications also need a test set of images for proof of the vision system’s reliability. The size of this test set depends on the particular application, and needs to be large enough to be statistically significant. Assuming the DL validation or testing set needs to be equally statistically significant (i.e., the same number of images as the test set for traditional machine vision), then the training image set will need to be 4 to 9 times as large as this test/validation image set.
So, when should traditional machine vision programing (aka rule based) be used and when should DL be used?
If high accuracy is needed in finding a part’s location or determining a dimension, then only traditional machine vision programming will work. DL is not designed to provide quantitatively accurate results.
People familiar with both traditional machine vision programming and DL tend to hold to the opinion that if a rule based approach will clearly work, that is the better way to proceed. Where rules are harder to formulate, then DL may be advantageous.
For example, finding random defects (e.g., scratches, nicks, pits, etc.) on a product has proven to be very difficult to formulate a set of rules that give high reliability in image processing. This is one area where DL can excel. Another area is working with agricultural or other natural objects (e.g., grading for shape or for blemishes or distinguishing the health of plants in the field) which, while very similar, are all somewhat different. Again, rules can be difficult to formulate and DL may be more tractable.
What does the future hold for image processing? The rate of new primitive image processing algorithms will be relatively slow. The development of new image processing tools for machine vision applications will also moderate. ML will continue to advance by becoming easier to train and deploy and by expanding the functions it can employ, possibly even as far as making measurements. Even now, there are demonstration (research) applications that can write computer code from a description of the requirements. While not ready for general use today, this technology will someday be available to address very challenging applications.
Looking for a reprint of this article?
From high-res PDFs to custom plaques, order your copy today!






